


Data Stack – Five must-have layers of a Modern Analytics Platform.
Data Shorts — Series of Interconnected Layers.


Prologue
Life is a journey of interconnected stages. From childhood to adulthood, each phase builds upon the last, shaping who I’ve become. The lessons I’ve learned, the experiences I’ve gathered, and the skills I’ve developed all form layers — stacked like bricks in a well-structured foundation. Skip a step, and things start to crumble. A modern analytics platform follows the same principle.
Right now, I see this period of writing as my offseason. Like an NBA player stepping away from the spotlight, refining their craft, and preparing for the next season, I find myself in a similar phase. After my five-part series on the Interior Walls of Data Platforms, I stood at an inflection point. I had spent months dissecting the internal structures of data ecosystems, and now I was ready for something bigger.
I’m deep into a more complex undertaking — a six-part series on Medallion Architecture projects in Fabric. But while that’s still in motion, I wanted to put down some thoughts forming in the back of my mind.
We recently wrapped up an analytics project for one of our esteemed clients in Downtown Seattle—one of those engagements that challenges you to think beyond solving technical problems. As I worked through the final deliverables, something clicked: patterns.
Across the various data platforms I’ve helped build — different industries, different use cases, yet the same underlying structure. It was like staring at a map of my professional journey. I started noticing how these platforms were layered, how each component played a role, how they all connected like athletes in a relay race — each passing the baton seamlessly to the next.
And just like in a relay, if even a single runner (layer) is missing, the entire race (data ecosystem) is compromised.
That’s when I knew — this wasn’t just a coincidence.
NB: Every organization’s data platform is unique, and the ideas I share from here on are meant to inspire, not dictate, how you should build yours.
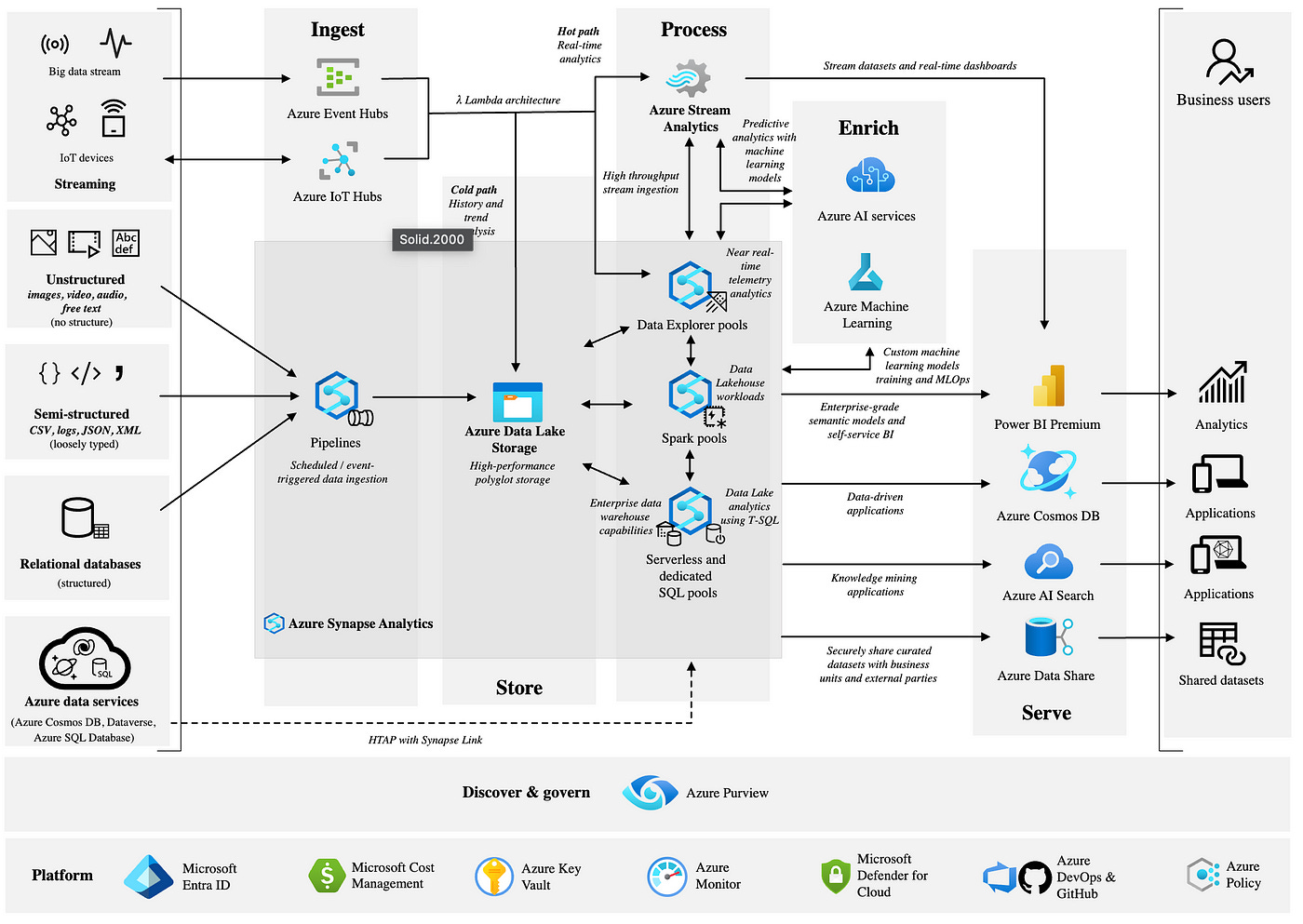
Introduction
A well-designed data platform is like a meticulously planned building — each layer serving a specific purpose to ensure stability, functionality, and adaptability. But hold on — what exactly is a data platform?
At its core, a data platform is more than just a storage system. “It is the engine that powers modern organizations, orchestrating the collection, cleansing, transformation, and application of data to generate actionable business insights”. Think of it as a well-structured library — where books (data) are systematically stored, cataloged, and made accessible to readers (users) who need knowledge at the right time.
But here’s the reality — not all data platforms are created equal. Without a structured approach, businesses struggle with data silos, poor governance, security risks, and inefficient analytics. Over the years, I’ve seen firsthand how organizations wrestle with these challenges. The solution? A platform built with the proper layers — each playing a role, each connected like pieces of a well-oiled machine.
Data as a Service
Not long ago, I had a conversation with a mentor who had been in the industry for decades. He told me something I remember from our convo:
“Years ago, companies saw data platforms as just another backend system — a means to an end. Now, they’re treating them like software products, dedicating resources to maintain and optimize them like any other critical business function.”

And he’s right. Data-first companies now embrace data platforms, not as a passive storage system but as an active, evolving service — a machine that collects, processes, and operationalizes data at scale. More organizations are shifting towards data mesh architectures, treating data as a product rather than just an asset. The role of a data platform has evolved into something far more sophisticated:
✅ An engine for decision-making
✅ A foundation for AI and analytics
✅ A governance framework for security and compliance
In my recent projects, I’ve seen firsthand how companies redefine their approach to data platforms — no longer just storing data but treating them as self-sustaining ecosystems.

Chapter 1 — The Challenges
What is life without challenges? They test us, shape us, and ultimately make us better. It’s no different in the world of data. Every organization aspires to be “data-driven,” but without the right foundation, that dream quickly turns into…..well a nightmare!.
The Challenges— I’ve seen firsthand the struggles that companies face when they lack a structured data platform. I’ve also been fortunate to work alongside teams that have rebuilt broken systems.
❌ Data Silos Everywhere — One department has customer insights locked in a CRM, another has financial records buried in spreadsheets, and marketing is flying blind with fragmented reports. Without a unified data platform, these silos make cross-functional collaboration painfully inefficient.
❌ Missed Opportunities — Businesses sit on mountains of data but fail to tap into its full potential. Without a solid data foundation, insights remain hidden, and critical decisions are made on gut instinct rather than facts.
❌ Security & Governance Risks — Poorly structured data leads to compliance nightmares. Sensitive data gets stored in places it shouldn’t, access controls are weak, and organizations open themselves up to breaches, fines, and reputational damage.
❌ Slow & Inefficient Analytics — When data isn’t properly structured, simple reporting turns into a tedious, time-consuming process. Instead of answering strategic questions in minutes, teams waste hours or even days just pulling the right data together.
The truth is, that bad data systems don’t just inconvenience a company — they cost millions in lost efficiency, missed opportunities, and security risks.
✅ The Fix — So what’s the fix to this issue? That’s where the five essential layers come into play. These layers don’t just organize data; they empower businesses to unlock their full analytical potential.
Let’s dive in!

Chapter 2— The Data Ingestion Layer
I was watching a TED Talk by Chimamanda Ngozi Adichie about “The Danger of a Single Story.” She spoke about how hearing just one perspective about a person, a culture, or an experience can lead to a dangerously incomplete understanding of reality. When a single narrative is told repeatedly, it shapes perception, often leading to bias, misinterpretation, and misinformation.

That made me think about data ingestion — the first and most fundamental layer of any data platform. Just as a single story limits our understanding, “sometimes relying on a single data source provides an incomplete picture. Without extracting data from multiple sources, we risk drawing misleading insights, making flawed decisions, and failing to see the bigger picture, breaking one of the dimensions of data quality — “Completeness”.
Data ingestion? — At its core, data ingestion is the process of collecting and importing data from various sources into a central repository — whether a database, data warehouse, or lakehouse — for storage, processing, and analysis. It is the pipeline that feeds everything downstream, ensuring we have the necessary inputs for transformation, modeling, and reporting.
But here’s where it gets tricky. Data ingestion is rarely straightforward. Modern enterprises don’t just deal with structured data from clean relational databases. They ingest:
• Transactional records from databases like Oracle and PostgreSQL
• Customer interactions from CRM tools like Salesforce
• Logs and telemetry data from IoT sensors and streaming devices
• Real-time data from APIs like Spotify or OpenWeather
Every organization has a unique data landscape, requiring tailored ingestion strategies to connect these disparate sources into a unified system.
The Two Modes of Ingestion
In my previous articles on Interior Walls of Data Platforms, I mentioned the two fundamental ways data is ingested into a platform:
Batch Processing — Data is extracted at scheduled intervals — Ideal for historical reporting and Real-Time Streaming — Data is ingested continuously — Used for real-time dashboards.
Hybrid — Many modern businesses need both, blending historical analysis with real-time insights. Think about how a ride-sharing app works:
Historical batch data helps analyze long-term trends (e.g., peak ride times, driver performance). Real-time streaming data ensures live tracking of drivers and surge pricing updates.
To achieve this, data teams leverage specialized tools depending on their needs:
• Batch Ingestion: Azure Data Factory, AWS Glue, Fabric Data Factory, Talend
• Real-Time Streaming: Apache Kafka, AWS Kinesis, Azure Event Hubs
• Orchestration & Automation: Apache Airflow, Prefect, Dagster
These tools form the spinal cord of the ingestion layer, ensuring data moves reliably, securely, and efficiently into the platform.
Without a strong ingestion layer, everything else falls apart. Bad data in = bad insights out.
Let’s picture a financial analytics platform that only ingests transaction data from a bank’s web portal but ignores data from their mobile app. Their reports would be incomplete, misrepresenting customer behavior. Or a healthcare analytics system that only ingests structured patient records but ignores unstructured doctor’s notes — critical patterns might be missed.
A well-designed ingestion layer ensures we aren’t working with a “single story” but a complete, multi-faceted narrative.
Chapter 3— The Storage & Processing Layer
Once data is ingested, you need a place to store it, process it, and make it readily available for analysis. This is where the Data Storage & Processing Layer comes in. Think of it like a city’s infrastructure — if ingestion is how raw materials arrive at the port, storage is where those materials are sorted, preserved, and made accessible before they’re turned into something useful.

From my professional experience, storage isn’t just about where data lives — it’s about how quickly you can access it, how efficiently you can process it, and how securely you can keep it.
Structured vs. Unstructured Data
Not all data is created equal. Some datasets arrive in clean, structured tables — think relational databases, financial transactions, customer records. Others? Messy, unstructured blobs — videos, PDFs, IoT sensor logs, social media feeds.
Modern platforms need to handle both efficiently. This is why storage solutions have evolved into three main categories:
1. Data Warehouses → Best for structured, relational data. Optimized for fast queries, BI reporting, and analytics. (Examples: Snowflake, Redshift, Synapse Analytics).
2. Data Lakes → Best for unstructured, semi-structured, and raw data. Used for big data processing, machine learning, and flexible storage. (Examples: Azure Data Lake, Amazon S3, Fabric OneLake.)
3. Data Lakehouses → A hybrid of both, giving you the structured querying of a warehouse with the flexibility of a lake. (Example: Databricks, Fabric OneLake.)
Choosing between them? It depends on your business needs. But here’s the reality: You can’t build a modern data platform without investing in cloud storage and compute.
Cloud Storage Is the Future
Gone are the days of on-premises servers struggling to keep up with growing data demands. Cloud platforms offer scalability, elasticity, and cost efficiency that traditional storage simply can’t match. Companies are migrating their entire data ecosystems to the cloud, leveraging solutions like: Azure Data Lake, Amazon S3, Google Cloud Storage and Fabric OneLake.
With the rise of serverless compute and on-demand storage, businesses can scale up or down instantly — paying only for what they use.
Storage Is More Than Just Capacity
When evaluating storage solutions, capacity is only one piece of the puzzle. The real questions are:
✅ Performance — How fast can you retrieve and process data?
✅ Cost Efficiency — Are you overpaying for storage you don’t use?
✅ Security & Compliance — How well is your data protected?
In the real world, businesses often blend multiple storage solutions to balance cost and performance. A company might store frequently accessed data in a high-performance warehouse (like Snowflake) while keeping historical raw data in a cheaper data lake (like S3).
Data storage is not just a technical decision — it’s a strategic one. The right choice will define how efficiently your analytics, AI models, and business decisions operate.
Chapter 4 — The Modelling & Transformation Layer
I remember managing a data pipeline for one of my clients that ran perfectly — at least, that’s what we thought. The data flowed, the reports loaded, and everything looked great. But then, I ran a simple sum on the final dataset during QA, and the numbers were off. -_-

Turns out, buried deep in the raw dataset were missing values, and incorrectly formatted timestamps that completely skewed the analysis.
Atits core, data transformation is about preparing raw data for analysis. It’s where you clean, standardize, and apply business rules to make sure the data is accurate and meaningful. Data modeling, on the other hand, is about organizing data for efficient storage and retrieval — structuring it in a way that makes sense for analysis and reporting. Think of transformation as prepping ingredients in a kitchen, while modeling is designing the layout of the restaurant.
Importance Of This Layer
Without proper transformation and modeling, reports might look fine on the surface, but they collapse under scrutiny, leading to bad decisions based on inaccurate data. This is where ETL (Extract, Transform, Load) vs. ELT (Extract, Load, Transform) comes into play. Traditional ETL processes clean and transform data before loading it into storage, while modern ELT pipelines take advantage of cloud-scale compute power by first loading raw data and transforming it later for flexibility and speed.
Key Functions of This Layer:
✅ Data Cleaning — Removing duplicates, fixing inconsistencies, and standardizing formats.
✅ Schema Enforcement — Ensuring data conforms to predefined structures.
✅ Business Logic Application — Converting raw numbers into meaningful metrics.
✅ Data Modeling — Structuring data into star schemas, snowflake schemas, or data vault models for optimized querying.
Every data team relies on a mix of industry-leading tools for transformation and modeling:
• Apache Airflow — Workflow orchestration for ETL/ELT pipelines.
• dbt (Data Build Tool) — SQL-based transformation for modern analytics.
• Databricks — Big data transformation with Spark.
I’ve seen organizations build cutting-edge platforms only to fall apart at this stage. Data transformation and modeling aren’t just technical steps — they are the foundation of data quality, governance, and trust.
Because at the end of the day, it doesn’t matter how much data you collect if you can’t turn it into something reliable.
Chapter 5 — The Analytics & Consumption Layer
Ionce worked with a client who, despite having access to a well-built data mart, kept asking for “just one more report.” His internal team had all the data they needed, but it was scattered across tables and dashboards that didn’t quite tell a complete story. The client wasn’t looking for more data — he was looking for clarity.

This is what the Analytics layer does — it translates processed data into insight. If your data platform were a book, this layer would be the cover, the title, and the “summary” — the part that makes the data engaging and consumable. Without it, all the effort spent collecting, storing, and transforming data remains locked away in technical obscurity.
Actionable Insights!
The real value of a modern data platform comes when businesses can extract insights and use them to drive decisions. Different teams consume data in different ways:
✅ Executives need high-level dashboards with KPIs to track business performance.
✅ Analysts rely on SQL queries and visualization tools to explore trends.
✅ Data Scientists build AI/ML models that predict outcomes and optimize operations.
… and all that fun stuff.
Before I move on to the last layer — Semantic Layer
The Semantic Layer is indeed crucial in modern data platforms. It provides a consistent, unified view of key business metrics across the organization. Think of it as the “translator” between raw data and meaningful business insights. Without it, different departments or teams might calculate the same metric in varying ways, leading to confusion, misalignment, and errors in decision-making. Essentially, the semantic layer turns complex data into something intuitive and understandable for everyone.
Note: It enables business users to have access to the same business logic, and provides data engineers and analysts with a central point of control over how metrics are defined.
Oh, let’s talk about the BI tools, which fall into two categories
Self-Service vs. Enterprise Analytics
• Self-Service Analytics (Power BI, Tableau, Looker) empower business users to explore data on their own without technical dependencies.
• Enterprise Analytics (Fabric Warehouse, Snowflake, Google BigQuery) focus on large-scale, governed reporting and AI-driven insights.
Some of the top tools I’ve seen in the industry include: Power BI, Tableau, Looker and Mode Analytics.
A well-designed Analytics layer is the bridge between processed data and real business value. Because at the end of the day, data isn’t about numbers — it’s about decisions.
In my personal opinion, if your final data doesn’t help people see, understand, and act, then it’s just another collection of stored information waiting to be forgotten.
Chapter 6: The Governance & Security Layer
It’s easy to forget about governance until things go wrong. Data governance isn’t just a “nice-to-have” — it’s the backbone of a well-functioning, secure data platform. It’s the process that ensures your data is not only available and usable but also secure and compliant. Think of it as the rulebook for managing your data — who gets to access it, how it’s used, and when it gets retired.

Effective data governance involves a combination of people, processes, and tools that work together to define policies, enforce rules, and maintain control. You need clear answers to questions like:
• How is data created, collected, and processed?
• Who has permission to access this data?
• What data is relevant for each role within the organization?
• Where is this data stored?
• When is it time to retire old data?
But the importance of data governance doesn’t stop there. It is directly tied to security. Without the right access controls, encryption, and tracking, your organization is vulnerable to breaches and compliance failures. As companies navigate increasing regulatory requirements like GDPR, CCPA, and HIPAA, data governance and security measures must go hand-in-hand.
Implementing frameworks like RBAC (Role-Based Access Control) ensures only authorized individuals have access to sensitive data, while data encryption secures data in transit and at rest. Lineage tracking provides a clear audit trail of where the data came from, who has touched it, and how it’s been used.
In the tool landscape, solutions like Azure Purview, AWS Lake Formation, and Fabric Security help automate governance, security, and compliance measures. They give you control over data access, lineage, and policy enforcement, making sure that your data platform is not only efficient but also secure.
Data governance is about trust. It ensures that all the hard work put into collecting, processing, and analyzing data doesn’t go to waste — and that it remains safe, compliant, and valuable for business use.
Conclusion
In this journey through the layers of a modern data platform, we’ve explored the foundational components that make up an agile, secure, and scalable system. From data ingestion to storage, transformation, analysis, and governance, each layer builds upon the other, creating an interconnected ecosystem where data flows seamlessly across the platform.
A well-architected data platform isn’t just about handling large amounts of data — it’s about providing the structure that empowers organizations to derive meaningful insights, maintain compliance, and ensure data security.
List of Inspirations
Through my journey in the industry, I’ve drawn inspiration from various sources, including hands-on experiences, failures, mentorship, consulting projects, and continuous learning. Each project and interaction has shaped my perspective on building effective data systems, transforming challenges into growth.
Socials
Join me on LinkedIn -Patrick B.O
Patrick B. Okare serves as the Solutions Data Architect / Lead Data Engineer at KareTech Analytics, he specializes in steering transformative cross-regional data analytics initiatives spanning diverse industries. With a focus on data integration, engineering and data management, he operates alongside a team of forward-thinking technologists and domain experts. Together, we expedite the achievement of impactful business results for clients, partners, and the broader community.