

Data Quality — The Path To Striking Gold in Your Lakehouse.
Unlocking the Power of Data Quality in Your Organization.

Unlocking the Power of Data Quality in Your Organization.
Prologue
A little backstory: Remember “SomeRandomCompany” from the final chapter in our trilogy? Let’s bring them back into focus in this Spin-Off.
“SomeRandomCompany” is a fictional firm in California's Sports and entertainment industry. It operates a multi-million-dollar data farm, housing petabytes of valuable information amassed from the operational systems of American NFL, UFC, NBA, MLS, MLB, and boxing events, along with insights gathered from major music streaming platforms.
Their business model centers around harvesting and reselling data to third parties, empowering brands to tailor products and create advertisements predicated on specific demographics.
It’s 9 a.m. on a Monday when a bombshell drops: The firm has been found inflating its financial figures, which, in turn, artificially boosted stock performance. Adding fuel to the fire, they have been accused of breaching CCPR rules by selling data outside the authorized region. As the news spreads, stock prices plummet on the NASDAQ, lawsuits flood in, and the company’s reputation hit substantially.
In the wake of this turmoil, an emergency response is initiated post-board meeting, with a third-party audit team swooping in to unveil a plethora of data issues that precipitated the scandal — let us dub these a series of “honest mistakes.” — A disconcerting predicament indeed!
It’s been four months since our Medallion Architecture Trilogy concluded, giving me time to reflect on what comes next. Not every great story warrants a SPIN OFF, but this one doesn’t just warrant it — It demands it.
This is “The Path to Striking Gold” on Data Platforms.

Let’s begin our story.
Introduction
Garbage in, Garbage Out is a term that originated in the mid-20th century as electronic computing emerged. Although Charles Babbage invented the concept of the modern computer, later technologists popularized the phrase. The idea remains timeless: what you input into a system directly impacts what you get.
This analogy spans all facets of modern life. The content you consume shapes your thoughts, the food you eat affects your health, and in manufacturing, raw materials dictate the quality of the final product.
Data, in many ways, is a “product” too. An organization can invest in cutting-edge big data technologies, hire top-notch developers, and have the guidance of domain experts. However, the entire structure is compromised if the production data is poor and the metrics are wrong. Efforts, resources, and time are all squandered. Storing data in a lakehouse achieves little if the quality is flawed in the semantic layer.
Data products play a pivotal role in driving customer segmentation, performance analysis, and predictive analytics. But at the heart of these products is the one thing that makes or breaks them — DATA QUALITY.
NB: Skip to Chapter 5, if you are here just for the Spin Off to the Spotify Trilogy.
Chapter 1: Why Data Quality Matters?
Data quality is the hidden gem of data architecture — the foundation upon which the brilliance of a data-driven organization is built. Like gold mined from the depths of the earth, raw data must be refined, cleansed, and shaped to unlock its true value. Without quality, your data platform — be it a lakehouse or data warehouse — crumbles under the weight of inaccurate insights and flawed decisions.
Storing billions of records in your lakehouse means little if the data isn’t reliable. Poor-quality data taints every decision and insight, transforming opportunities into liabilities.
The Real-World Consequences
At the start of this story, we saw the impact of inadequate data quality at “SomeRandomCompany.” Their reputation took a hit when unreliable data led to flawed analytics, which in turn produced misguided strategies. The cost was not just financial but reputational.
On a strategic level, bad data quality:
• Misleads Decisions: Inaccurate insights lead to costly mistakes.
• Damages Reputation: Companies risk losing customer trust and market position.
• Jeopardizes Compliance: In regulated industries like finance or healthcare, errors could result in hefty fines or the loss of licenses.
Operationally, poor data quality means inefficiencies, wasted resources, and frustrated stakeholders. In industries like healthcare, banking, or government, the stakes are even higher, where wrong numbers could directly affect lives or public trust.
Drawing insights from a recent event to illustrate my point.
During the 2024 U.S. election, real-time visuals of poll numbers, voter turnout, and demographics were displayed nationwide. Behind those seamless graphics was an intricate web of analysts ensuring every figure — from swing state margins to total votes — was accurate.

Now imagine the fallout if the numbers for a key state were incorrect. The misstep wouldn’t just undermine confidence in the election but could ignite a political crisis. It’s a stark reminder of how critical data quality is in high-stakes scenarios. The same applies to businesses: whether it’s election results or financial transactions, poor-quality data has real-world consequences.
The Case for Data Quality at Scale
Ensuring quality across terabytes of data isn’t easy. It requires a strategic blend of:
1. People: Teams trained in data governance and management.
2. Processes: Defined workflows for validation, cleansing, and enrichment.
3. Technology: Scalable tools to automate quality checks and monitor issues in real-time.
From Data to Insight
So, how do you determine data quality? By embracing a framework where data is treated as a product. Each dataset must meet the standards of accuracy, completeness, consistency, and timeliness before being deemed fit for use.
Data quality isn’t just about avoiding “garbage out.” It’s about ensuring that your data becomes the cornerstone of impactful decisions, innovation, and growth. As we’ll explore in the coming chapters, mastering data quality isn’t a one-time effort — it’s a journey that demands continuous vigilance.
Chapter 2: Data As A Product
Data can be likened to a masterfully crafted product. Just as the quality of raw materials determines the durability of a building, the quality of raw data influences the reliability of insights derived from it.
Treating data as a product ensures it becomes a valuable asset rather than digital clutter.
Data as Insights
Take Facebook as an example: the platform collects data on user behaviour — likes, clicks, and browsing history — to create personalized recommendations and offers. This data doesn’t directly generate revenue but fuels insights that help the company deepen user engagement, increase ad revenue, and identify opportunities for growth. The result? A competitive edge driven by data-informed strategies.
Another example is Amazon, which utilizes purchasing data to power its recommendation engine. By treating this data as a product, Amazon tailors suggestions for millions of users, enhancing customer experience and driving sales.
NY Taxi Case Study: Data as a Product
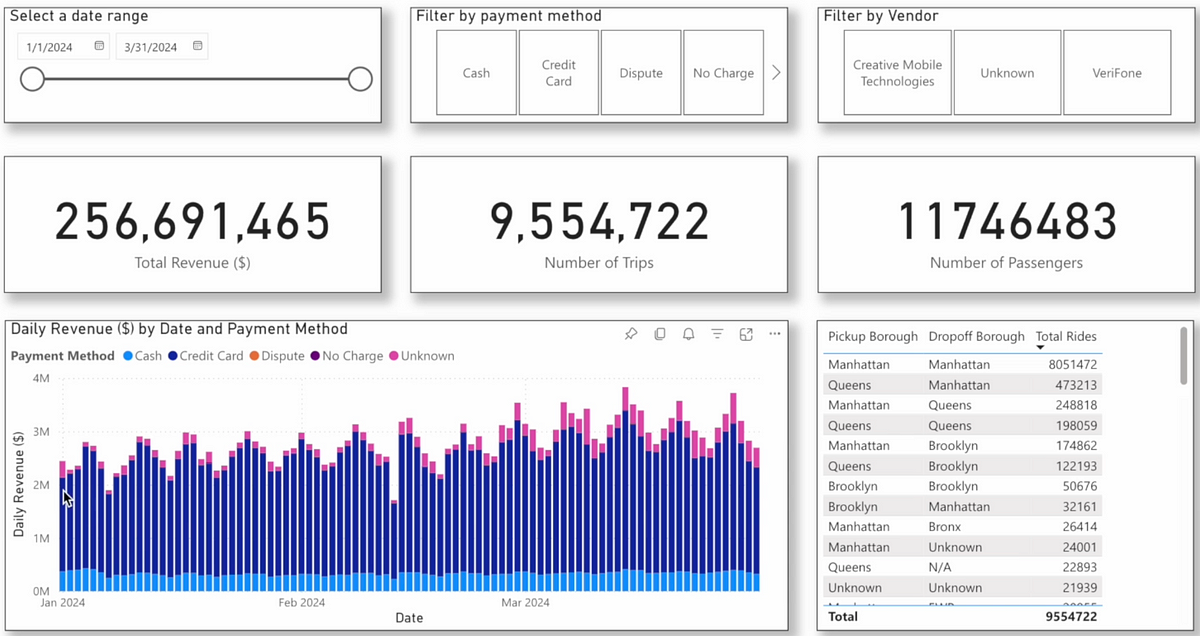
The screenshot above showcases a Power BI dashboard powered by the New York Taxi Dataset, which houses 3–5+ million records behind the scenes in my Lakehouse on Databricks. This dashboard is not just a visual representation; it’s the culmination of a rigorous ETL process involving cleansing, validation, and verification at every stage.
Why is this important?
Without ensuring data quality, the metrics you see ABOVE — such as the impressive $256,691,465 in revenue for Q1— could be completely wrong. Imagine the consequences if the taxi company believed they were raking in profits, only to later discover they were reporting on flawed, inaccurate data. Such errors can lead to disastrous decisions, from misallocated resources to eroded stakeholder trust.
This mini case study underscores the critical role of treating data as a product — crafted with care, refined for accuracy, and optimized for consumption — ensuring reliable insights that drive informed decision-making.
What Defines a Data Product?
A data product combines three key elements:
1. Data Sets: These may include tables, views, ML models, or streams — raw or curated — ready to serve insights.
2. Domain Model: A semantic layer that abstracts technical complexities and presents business-friendly terms, calculations, and metrics.
3. Access Mechanisms: APIs, dashboards, or visualizations with enforced access controls for secure data consumption.
From Business Needs to Technology
Before jumping to technical implementation, it’s crucial to understand the business context. Data products are designed to solve business challenges — be it by optimizing supply chains, uncovering new markets, or predicting customer behaviour. Aligning data products with these goals ensures they deliver actionable insights and measurable value.
By adopting the “data as a product” mindset, businesses can transform raw data into a strategic resource. This approach not only supports informed decision-making but also fuels innovation, helping organizations thrive in a data-driven world.
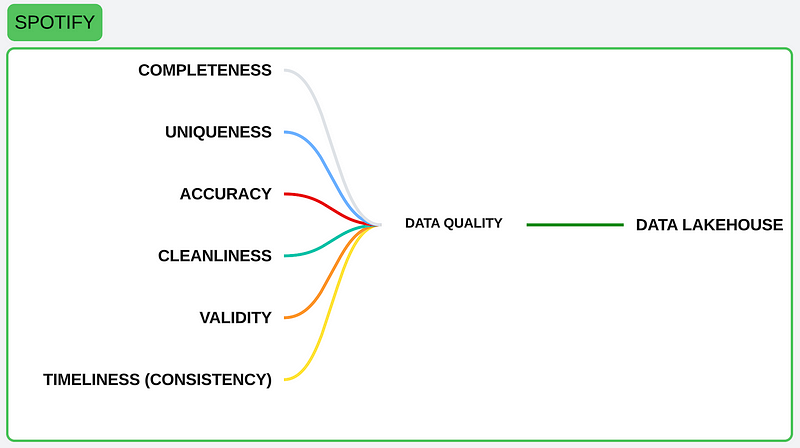
Chapter 3: Six Dimensions of Data Quality
In the realm of data management, quality is not just a buzzword; it is the cornerstone upon which the utility and reliability of information are built. This chapter delves into the six core principles of data quality, principles that were also instrumental in our Spotify project.
By adhering to these principles, we ensured that the data in our lakehouse was not just present but purposeful, not just stored but strategic.
Data Completeness
Definition: “Completeness — Data should be representative, providing a full picture of real-world conditions.”
Completeness concerns whether a dataset contains all necessary records, without missing values or gaps. A complete dataset is essential for meaningful analysis and decision-making. Techniques for improving completeness include inputting missing values, merging sources, or incorporating external reference datasets (e.g. Look-ups).

In the real world, completeness is essential in any financial data product that includes historical transaction data tied to customer purchases. If product dimensions lack details for certain items, this incomplete data can distort insights into customer preferences or sales trends, potentially creating significant blind spots in analysis.
Completeness in Sports & Music Data Product
Picture an analytics data product for a sports organization tracking fan engagement with music playlists curated for NBA games. Let’s say “SomeRandomCompany” partners with music platforms to offer curated playlists synced with live game highlights.
The goal is to analyze how each track impacts fan engagement based on streaming volume during games and correlate it with game performance statistics.
In this case, “completeness means ensuring that every song played at every Sports game is accounted for.”
For example:
• Sports Playlists: Each game’s playlist data should include details of each song, artist, and genre and match every second of streaming activity during that game.
• Historical Data: To capture trends, historical data across multiple seasons and sports leagues (NBA, NFL, MLS) must be included, without gaps in-season games, teams, or fan demographics.
To conclude, If the dataset misses songs from specific games or overlooks certain fan segments, the dataset lacks completeness, leading to skewed analysis that could misrepresent how fans engage with the music content.
Data Uniqueness
Definition: Uniqueness — Each record should be distinct, ensuring no duplicates or overlaps within or across datasets.
Uniqueness ensures that every record in a dataset is distinct and free from duplication or overlap. It is the cornerstone of reliable analysis and trusted insights. Imagine trying to plan customer engagement strategies with multiple conflicting records for the same individual — it would lead to inefficiencies and errors.

A high uniqueness score reflects the absence of duplicates, enabling streamlined processes and robust decision-making. Maintaining uniqueness requires proactive steps, such as identifying overlaps, cleansing data, and deduplicating records.
For example, creating unique customer profiles not only enhances engagement strategies but also strengthens data governance and compliance efforts.
In practice, uniqueness builds the foundation for efficiency and accuracy in any domain. Whether it’s pinpointing one-of-a-kind customer insights or ensuring distinct entries in financial records, this dimension eliminates redundancies and fosters trust in the data ecosystem.
Bringing back the 2024 US Elections Analogy
Imagine if duplicate votes existed in the system. Performing aggregations on these duplicates by a particular voter in a certain region could lead to inflated vote counts, skewing results for critical swing states.

Such discrepancies would not only undermine public trust but also cast doubt on the legitimacy of the electoral process. Ensuring uniqueness in voter records is essential to maintain accurate tallies and uphold the integrity of democracy.
Data Cleanliness & Integrity
Definition: “Data cleanliness ensures that the data is free from errors, inconsistencies, and inaccuracies.”

Integrity, on the other hand, ensures that data remains reliable and correctly connected as it moves across systems, retaining the intended relationships between attributes. Together, they uphold the trustworthiness of enterprise data.
Example: Imagine a customer profile containing a name and multiple addresses. If an address loses its validity during a migration or transformation process, the profile becomes incomplete and unreliable, potentially leading to failed deliveries or inaccurate customer segmentation. This is why maintaining integrity and cleanliness is critical in the data journey.
Using my US Elections example
During the US elections, maintaining cleanliness and integrity in voter data is paramount. Suppose a voter record has conflicting addresses or invalid registration details due to data inconsistencies.

In that case, this could lead to miscounts or incorrect voter eligibility, disrupting the election process. Ensuring cleanliness would verify accurate addresses and details, while integrity ensures that voter data remains consistent and properly linked across systems — critical for a fair democratic process.
Finally, ensuring cleanliness and integrity isn’t just about fixing errors; it’s about building trust in data as a foundational element for decision-making and operational success.
Data Accuracy
Definition: Accuracy measures how closely data represents the real-world entities or events it describes. It ensures that the information is correct, precise, and reflective of reality, providing a reliable foundation for decision-making.

Accurate data eliminates the risks associated with errors or misrepresentations. For instance, an employee’s correct phone number ensures seamless communication, while inaccurate birth records might lead to ineligibility for certain benefits. Accuracy directly impacts the reliability of the processes, decisions, and outcomes that depend on it.
How to Achieve It:
• Validation Rules: Prevent inaccuracies by enforcing stringent validation checks at data entry points.
• Verification: Cross-check data against authentic sources, such as verifying customer bank details through transactions or certificates.
• Governance: Maintain accuracy throughout the data lifecycle with robust data governance practices, ensuring data remains unaltered and reliable as it moves across systems.
In the US Elections, accuracy is non-negotiable. Imagine if voter records contained incorrect details, such as mismatched names or outdated registration statuses. Even a minor inaccuracy could lead to disqualified votes or misrepresented demographic statistics, eroding trust in the electoral process. Accurate data ensures every eligible voter is counted correctly, enabling factually sound election results and reinforcing confidence in democracy.
Finally, high accuracy powers credible reporting trusted analytics, and successful outcomes — especially in regulated industries like healthcare, government and finance, where errors could lead to catastrophic consequences.
Data Timelineness & Consistency
Definition — Timeliness means ensuring that data is up-to-date, relevant, and ready when you need it.
Timeliness is like the precision timing of an athlete crossing the finish line or a musician hitting the right note at the right moment. Data must be up-to-date, relevant, and ready when you need it. Just as a race is won or lost in the final seconds, outdated data can lead to misinformed decisions. Whether it’s through incremental updates, scheduled refreshes, or real-time streaming, ensuring your data is always current is crucial for accurate analysis.

Imagine an athlete sprinting towards the finish line, the clock ticking down, every second counting. Timeliness in data works in much the same way — it’s all about being precise and on time. Just as a race can be won or lost in the final moments, outdated data can steer decisions off track. If your data isn’t current, it’s like running with one foot in the past, leading to misinformed decisions and missed opportunities. Whether it’s through incremental updates, scheduled refreshes, or real-time streaming, keeping data up-to-date ensures that your analysis is built on the freshest, most relevant information.
Then, there’s Consistency — the harmony of a perfectly orchestrated symphony, where every instrument must stay in tune to create a seamless performance. In the world of data, consistency is key. If your data isn’t coherent and compatible across various systems, it’s like a discordant note disrupting the entire composition. Data must be aligned in format, structure, and meaning, just like musicians sticking to the same key and rhythm. By implementing data standardization — consistent naming conventions, formats, and units of measurement — you create a unified system where all pieces fit together, making data reliable and ready for decision-making.

For example, picture a healthcare system relying on real-time patient data for life-or-death decisions. If the data isn’t timely, outdated medical records could lead to catastrophic mistakes. Prescribing the wrong treatment, missing critical allergies, or overlooking urgent changes in a patient’s condition can be the difference between life and death. By ensuring real-time updates and scheduled refreshes, healthcare providers can access the latest data, empowering them to make accurate, timely decisions when they matter most.
Now, let’s look at consistency within that same healthcare system. Imagine a situation where different systems use varying formats for patient data — birthdates in one system are listed as MM/DD/YYYY, while another uses DD/MM/YYYY. Medication dosages may be measured in milligrams in one record, and grams in another. This inconsistency can confuse healthcare providers, leading to conflicting diagnoses or, worse, unsafe treatment decisions. By standardizing formats, adopting consistent naming conventions, and aligning units of measurement, you ensure that patient data is always accurate, consistent, and easy to interpret, no matter where it’s accessed or who’s using it.
Data Validity
Definition: Validity in data ensures that the information aligns with the expected rules, standards, or domain requirements.
Validity is like a professional sports team adhering to a meticulously crafted playbook. Every player must understand their role and execute according to plan. Similarly, for data to be valuable, it must meet specific criteria defined by the domain — whether it’s adhering to format standards or matching expected values.
For instance, a ZIP code is only valid if it contains the correct characters for its region, just like a month is valid only if it corresponds to the correct names in a calendar. Valid data means following the game plan; it’s not just about having the right numbers — it’s about having the right numbers in the right form.
Without valid data, the entire dataset can fall apart. It’s akin to an athlete who doesn’t follow the rules — throwing off the entire team’s performance. Invalid data, whether it’s in the form of misspelled names, incorrect dates, or inconsistent units of measurement, disrupts the integrity of your analysis, leading to flawed conclusions and unreliable results. Like a misplaced pass in a high-stakes game, invalid data creates confusion and undermines the reliability of the entire dataset.

To avoid this, businesses must establish clear business rules that define what valid data looks like. These rules are the playbook for ensuring that every data point is accurate, meaningful, and consistent with the expected standards. Once those rules are in place, data validation tools can be used to identify invalid entries and either correct or exclude them.
By enforcing these rules consistently, you safeguard the completeness and accuracy of your data, ensuring that decision-makers can rely on it for sound conclusions.
In the aftermath of the scandal at SomeRandomCompany, where invalid data was manipulated to mislead stakeholders, the focus must now shift to the validity of every data point. When data isn’t valid, you risk repeating past mistakes — making decisions based on information that simply doesn’t match reality.
Before we get to the Spotify project section, let’s quickly talk about how we can improve the health of our data.
Chapter 4: How to Improve the Health of Your Data?
In the wake of the crisis at SomeRandomCompany, where data manipulation ran rampant, the focus now turns to restoring the health of data — the very lifeblood of any organization. The stakes are high. As we’ve seen, bad data can lead to broken trust, poor decision-making, and severe reputational damage. But how do we turn things around and ensure that our data is healthy, reliable, and ready to empower decision-makers?
It’s about taking action and embracing a multi-pronged approach, where tools and practices come together to create a robust data quality management system. From automated quality checks that ensure accuracy and consistency at every stage, to metadata management that provides transparency into data lineage, there’s no single fix for data health — it’s a continuous effort.
Governance policies clarify roles and responsibilities for data ownership, ensuring that everyone knows their part in safeguarding the quality of data. With real-time monitoring through dashboards, data health can be tracked continuously, providing instant feedback on where things are going wrong and where corrections are needed.
I was reading a good article the other day, and I read that — There are two pivotal moments in the lifecycle of data: the moment it is created and the moment it is used. So True!!!
In the case of SomeRandomCompany, the data creation moments were far from perfect, leading to catastrophic consequences when the data was eventually used. To avoid such pitfalls, we must connect these two moments in time — ensuring that data is not only correctly created but also correctly managed until the very moment it is put to use.
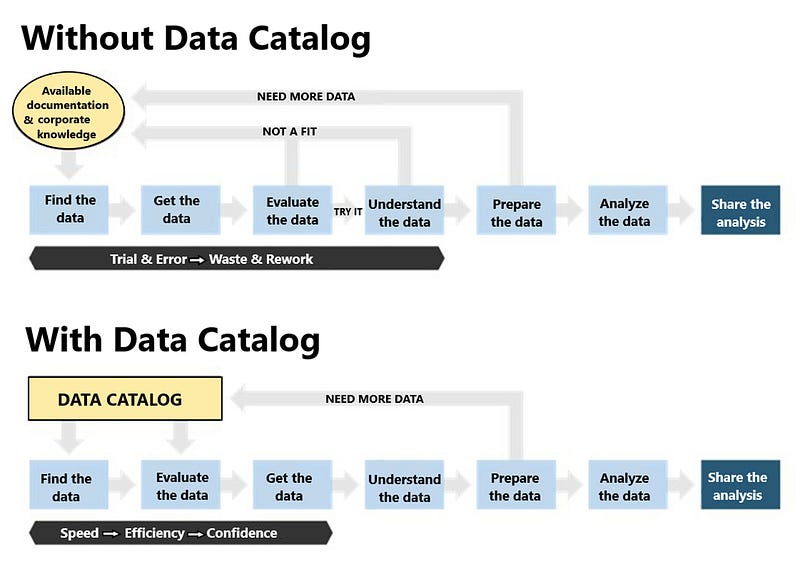
A comprehensive approach to data quality is essential, and metadata management, Data cataloging and data governance lay the foundation for success. When executed well, these practices not only restore trust but convert data into a true enterprise asset. It’s all about connecting the dots, from understanding data lineage and use cases to ensuring consistency and completeness.
4.1 Metadata Management and Cataloging
In the grand architecture of our Lakehouse story, metadata plays the role of a city planner, organizing and mapping out the landscape to ensure everything runs smoothly. Without metadata, your data platform can quickly become a labyrinth, making it nearly impossible to locate, trust, or use data effectively. Proper metadata management ensures that data is not only stored but also understood, tracked, and accessed seamlessly.
Tools & Technology
While my focus is often on principles and concepts, it would be remiss not to mention some standout tools that have made a mark in metadata management: Azure Purview, Alation, and Unity Catalog. Each of these tools provides unique capabilities to empower organizations to maintain clarity, structure, and governance over their data platforms.

Unity Catalog on Databricks: A Quick Discussion
Unity Catalog is like the master architect of metadata management within Databricks. It serves as a unified data governance solution, bringing consistency and control across all Databricks workspaces. Just as a city planner ensures zoning laws and infrastructure integrity, Unity Catalog ensures that your data governance framework aligns with industry regulations and best practices.
Key Features and Benefits
Data Access Control: Like a gated community, Unity Catalog enforces secure and controlled access to data. This fosters trust among users while maintaining compliance with regulations like GDPR and CCPA. :)
2. Data Lineage: Imagine tracking the history of every building in a city — from its blueprint to its construction and eventual use. Unity Catalog’s automated data lineage does exactly this for data, mapping its journey through pipelines. This transparency supports root cause analysis, and impact assessments, and ensures trust and reliability.
3. Data Auditing: Think of it as a city’s regulatory inspections, ensuring standards are met. Unity Catalog facilitates data auditing, providing accountability and ensuring compliance with governance standards.
4. Data Discoverability: A well-planned city allows its citizens to easily locate resources. Similarly, Unity Catalog enables quick and efficient data discovery and sharing through a unified model, empowering teams to find and use data without bottlenecks.
Why Metadata Management Matters
In the intricate design of a Lakehouse, metadata serves as the foundation that transforms chaos into order. Without tools like Unity Catalog, Azure Purview, or Alation, managing metadata across disparate systems would be like navigating a city without a map — time-consuming, frustrating, and prone to error.
To conclude, in our Lakehouse journey, think of metadata and cataloging tools as the architects who bring structure to the chaos of data. Tools like Unity Catalog provide the blueprint to ensure that your data is discoverable, trustworthy, and governed. Investing in strong metadata management practices today ensures your data platform remains resilient, compliant, and scalable for the future.
“With the groundwork laid and a solid understanding of the principles and concepts, let’s shift our focus to the Spotify Project, where we’ll see these ideas in action.”
Chapter 5: Data Quality in Lakehouse
As I’ve highlighted in past stories, data lakehouses merge the flexibility of data lakes with the reliability of data warehouses. From my experience with clients, this architecture frequently serves as the backbone for scalable, efficient data management systems while ensuring robust data quality standards.

In our Spotify Trilogy, we structured the lakehouse into three layers—Bronze, Silver, and Gold—each with its data quality controls. Leveraging the six dimensions of data quality we discussed earlier, we meticulously designed a framework to uphold quality at every stage.
Bronze Tier: The Foundation
After initially extracting our data in the landing zone, the Bronze layer was the entry point for raw data ingested from Spotify. It functioned as the first line of defence, ensuring data completeness, accuracy, and consistency right from the source.
Here’s what I implemented:
• Checks for Completeness: I validated that all expected records from Spotify’s source systems were present.
• Duplicate Handling: Identifying, removing null values, standardization and removing duplicate records to maintain accuracy.
• Error Detection: Scanning for anomalies or corrupted records before data advanced further.
This stage ensures raw data integrity, laying the groundwork for higher-quality outputs. In practice, data owners and developers collaborate to enforce these quality standards to meet the requirements of business users.
Silver Tier: The Refinement
In the Silver layer, we processed raw data to create cleansed and enriched datasets. This stage emphasized accuracy, consistency, and completeness while aligning with business requirements.
My efforts included:
• Cleansing and Enrichment: Removing irrelevant fields and adding context to make the data more usable.
• Profiling: Evaluating data patterns to identify and address inconsistencies.
• Collaboration with Stakeholders: Working closely with the fictional business team :) to establish rules that reflect domain-specific insights.
By the time data left the Silver tier, it was ready to support advanced analytical queries and reporting needs.
Gold Tier: The Pinnacle
The Gold layer housed our data products, where only the highest-quality data resided. Here, the focus was on accuracy, consistency, completeness, and timeliness.
The steps I took included:
• Validation for Timeliness: Ensuring that data was up-to-date and aligned with business timelines. By scheduling the ETL jobs every 15 minutes.
• Comprehensive Quality Audits: Regular reviews to maintain adherence to established quality standards.
• Business Decision Support: Preparing data products ready for critical decision-making processes. e.g. By creating the two reports for the Spotify project.
The Gold layer exemplifies the culmination of our efforts, transforming raw data into actionable insights for “somerandomcompany”.
My Final Thoughts
Conclusion
Ensuring data quality in a lakehouse is not a one-and-done activity — it’s a continuous, iterative process. By embedding a quality framework, we can monitor our data’s state and flagged deviations. For example, data failing to meet predefined thresholds can be quarantined for review.
From my experience, fixing data quality issues at the source is the best approach. Resolving errors upstream prevents contamination and reduces the risk of the same issue recurring across layers.
Finally, keep in mind that as your organization evolves, so too must your data quality framework. Continuous monitoring, validation, and updates are essential to ensure your systems scale alongside your business. With high-quality data, you’re better positioned to make informed decisions, foster growth, and unlock the full potential of your data lakehouse.
Epilogue
What if the company from the beginning of our story had implemented a robust data quality framework earlier? Perhaps they could have avoided losing millions, salvaged their reputation, and maintained stakeholder trust — But alas, we’ll never truly know, will we? 🙂
You might wonder — what happened to “somerandomcompany” after their data fiasco. Thankfully, they learned from their mistakes. They revamped their processes and embraced a comprehensive Data Management Framework.
The turnaround wasn’t easy, but the company emerged stronger, with data that was no longer a liability but a competitive advantage. Their story serves as a cautionary tale — a reminder that data quality isn’t a “nice-to-have” but a “must-have” for modern businesses.
As you reflect remember this: investing in data quality isn’t just about avoiding losses; it’s about unlocking the true potential of your data to drive success and innovation.
Stay tuned for the final Spin Off — Data Auditing.
Thank you for reading!
List of Inspirations
https://www.ibm.com/products/tutorials/6-pillars-of-data-quality-and-how-to-improve-your-data
https://www.collibra.com/us/en/blog/the-6-dimensions-of-data-quality
Socials
Join me on here Analytics at KareTech | LinkedIn -Patrick B.O
Patrick B. Okare serves as the Solutions Data Architect / Lead Data Engineer at KareTech Analytics, he specializes in steering transformative cross-regional data analytics initiatives spanning diverse industries. With a focus on data integration, engineering and data management, he operates alongside a team of forward-thinking technologists and domain experts. Together, we expedite the achievement of impactful business results for clients, partners, and the broader community.
